
type
status
date
slug
summary
tags
category
icon
password
似乎是第一篇不改变标签的攻击,不过是数据投毒
简单来说,攻击者从训练集合的基类中找到一个样本,使用特殊的修改之后使它满足下列条件:
- x与基类样本差别尽量小
- 在经过神经网络后,x与目标样本的激活值差别尽量小
生成这样的带毒样本后,在经过干净模型后,这个带毒样本会被错误分类为目标。但是若在干净+投毒的样本作为训练集中,由于专家标签会保证将其标签定为基类标签,而距离其在特征空间较近的目标类可能就由于决策边界的旋转而被分类为基类。
摘要
数据投毒是一种对机器学习模型的攻击方式,其中攻击者将样本添加到训练集中,从而在测试时操纵模型的表现。本文对神经网络的投毒攻击进行了探讨。我们提出使用“干净标签”攻击,即不需要攻击者对训练数据的标签有任何控制。这也是一种有目标攻击;其控制分类器在(特定)测试样本上的表现,而不会降低整体分类器的效果。例如,攻击者可以将看似无害的图像(已正确标记)添加到面部识别模型的训练集中,并在测试时操控指定人员的身份。这里攻击者不需要控制标签,只需将毒样本留在网络上并等待其被数据收集的爬虫抓取,就可以将毒样本输入到训练集中。
我们提出了一种基于优化的毒样本制作方法,并表明:在使用迁移学习时,只需一张带毒图像就可以控制分类器的表现。对于完整的端到端训练,我们提出了一种“水印(watermarking)”策略,该策略使用多个( ≈50 )带毒训练样本,保证毒害的可靠性。为演示我们的方法,我们从 CIFAR 数据集生成了“毒蛙”图像,并通过它们来操纵图像分类器。
1. 介绍
在将深度学习算法部署到高风险、安全关键(security-critical)型的应用程序之前,必须测试它们对对抗攻击的鲁棒性。深度神经网络(deep neural networks, DNN)中对抗样本的存在,引发了对这些分类器的安全性的争论 [Szegedy et al., 2013, Goodfellow et al., 2015, Biggio et al., 2013]。对抗样本(Adversarial examples)属于一类 逃逸攻击(evasion attacks)。逃逸攻击发生在测试时,其方法是修改一个干净的目标样本,从而时期避免被分类器检测到,或者导致错误的分类。然而,这些攻击并没有映射到特定的现实场景,其中攻击者无法控制测试时的数据。例如,假设一家零售商打算通过基于机器学习(ML)的垃圾邮件过滤器,将竞争对手的电子邮件标记为垃圾邮件。逃避攻击不适用这种情况,因为攻击者无法修改受害者的电子邮件。同样,攻击者可能无法更改在受监督条件下运行的人脸识别模型的输入,例如有人值守的安检台或建筑物入口。但这样的系统仍然容易受到数据投毒(data poisoning)攻击。这些攻击发生在训练其间,其旨在通过将精心构造的带毒样本(poison instances)插入训练数据,来暗中操控系统的表现。
本文研究了神经网络的有目标(targeted)中毒攻击,亦即,这些攻击旨在控制分类器在一个特定测试样本上的表现。例如,他们暗中操控一个面部识别模型,从而更改指定人的身份,或操纵垃圾邮件过滤器,以接收/拒绝攻击者选择的特定电子邮件。我们提出了一种不需要控制标签的干净标签(clean label)攻击;据一位专家观察者说,中毒的训练数据似乎被贴上了正确的标签。这使得攻击不仅难以检测,而且攻击者可以在无需对数据收集/标记过程进行任何内部访问的情况下,直接打开成功的大门。例如,攻击者可以将带毒图像放在网上,等待它们被从网络上收集数据的爬虫抓取。前面描述的零售商可以直接向组织内部人员发送电子邮件,就可以为垃圾邮件过滤器共享数据集。
1.1 相关工作
经典的投毒攻击不加选择地降低测试的准确性,而不是针对特定的样本,这使得它们很容易被检测到。虽然关于支持向量机(support vector machines)[Biggio et al., 2012] 或贝叶斯分类器(Bayesian classifiers)[Nelson et al., 2008] 的投毒攻击方面有一些相关研究,但针对深度神经网络(Deep Neural Networks, DNN)的投毒攻击的研究却寥寥无几。为数不多的现有研究已经证明,DNN 在抵御数据投毒攻击时会发生灾难性的失效。Steinhardt et al. [2017] 报告说,即使在强大的防御下,当允许攻击者对训练集进行 3% 的修改时,测试准确率也会降低 11%。Muñoz-González et al. [2017] 提出了一种基于反向梯度的生成毒样本的方法。为了加快生成中毒样本的过程,Yang et al. [2017] 开发了一种生成毒样本的生成器。
一种更危险的方法是让攻击者以特定的测试样本为目标。例如上面提到的零售商,除了要实现自己的目标之外,还不希望使垃圾邮件过滤器变得毫无作用,或者让受害者知道攻击的存在。最近的工作表明,具有很少量资源( ∼50 个训练样本)的有目标后门攻击 [Chen et al., 2017] 就会导致分类器在特殊测试样本中失败。Gu et al. [2017] 使用标记有特殊图案的错误标记图像训练网络,使分类器学习图案和类标签之间的关联。Liu et al. [2017] 训练了一个网络,以响应木马触发器(trojan trigger)。
这些攻击存在与逃逸攻击相同的缺点;他们需要修改测试时的样本,从而引发错误的预测。此外,大多数先前的工作都假设攻击者对训练集中样本的标记过程有一定程度的控制。这没有考虑真实世界的场景,其中训练集由人工审核员审核,审核人员会在每个示例出现时为其贴上标签,或者标签由外部进程分配(例如恶意软件检测器,通常会收集由第三方防病毒软件标记的实况(ground truth))。我们假设对标签函数的控制是一种直接的单次攻击(one-shot attack),其中带有翻转标签的目标样本就是为毒样本。对毒样本的过拟合能够确保目标样本在推理期间被错误分类。与我们自己最密切相关的工作是 Suciu et al. [2018],他们对针对神经网络的有目标攻击进行了研究。然而,他们的攻击要求毒物在每一个小批量(minibatch)中至少占 12.5%(最多 100%),这在实际可能是不现实的。相比之下,我们的攻击不需要对小批量训练过程进行任何控制,并且假设中毒占比要小得多(<0.1% vs. >12.5%)。
最后,我们注意到有几项工作从理论角度探讨了投毒问题。Mahloujifar and Mahmoody [2017],Mahloujifar et al. [2017] 从理论角度研究了投毒威胁模型,Diakonikolas et al. [2016] 考虑了分类器对训练数据扰动的鲁棒性。
1.2 贡献
这项工作中,我们研究了一种新型攻击,称作干净标签(clean-label)攻击,其中攻击者注入的训练样本由认证机构贴上干净的标签,而不是由攻击者自己贴上恶意标签。我们的策略假设攻击者并不知道训练数据,但知道模型及其参数。这种假设很合理,因为许多在标准数据集上预训练的经典网络,例如在 ImageNet 上训练的 ResNet [He et al., 2015] 或 Inception [Szegedy et al., 2014] 经常用作特征提取器。攻击者的目标是在网络在包含毒样本的增强数据集上重新训练后,该网络会将某个类别(例如恶意软件)中的特殊测试样本错误分类为指定的另一类(例如良性应用)。除了对目标的预期错误预测外,受害分类器的效果下降并不明显。这使得最先进的衡量训练样本(例如 Barreno et al. [2010]))性能影响的投毒防御都不起作用了。
有一种相似类型的攻击,对于仅在中毒数据集上重新训练网络的最后一个全连接层的场景,使用影响函数(influence functions)(Koh and Liang [2017]),可以达到成功率为 57% 。我们在 Koh and Liang [2017] 研究的迁移学习(transfer learning)场景下,提出了基于优化的干净标签攻击,但我们在相同的狗/鱼(dog-vs-fish)分类任务上实现了 100% 的攻击成功率。此外,据我们所知,我们首次研究了端到端训练(end-to-end training)场景下的干净标签投毒,其中网络的所有层都会被重新训练。通过可视化,我们表明:由于深度网络的表现力,这种情况要困难得多。根据可视化效果,我们在深度网络上设计了一个有 50 个毒样本的攻击,在端到端训练场景中的成功率高达 60% 。
*End to end 端到端训练的思想是将整个系统作为一个整体进行训练,从原始输入直接到最终输出,中间的各个组件共同学习和优化。这意味着输入数据会经过一系列的处理和转换,直到产生最终的输出结果,而这个过程中的所有组件都是共同训练的。
2. 一种简单的干净标签攻击
我们提出了一种基于优化的程序来构造带毒样本,当将其添加到训练数据中时,可以操纵分类器在测试时的表现。随后,我们将讨论如何增强这种简单攻击的威力。
攻击者首先从测试集中选择一个目标样本(target instance);一次成功的中毒攻击会使得此目标样本在测试期间被错误分类。接下来,攻击者从基类中采样一个基样本(base instance),并对其进行细微的更改,从而制作一个带毒样本(poison instance); 这种毒样本会被填入训练数据中,使得模型在测试时会用基标签(base label)来标记目标样本。最后,该模型在中毒数据集(干净数据集 + 带毒样本)上进行训练。如果模型测试时将目标样本误认为是基类,则认为中毒攻击成功。
2.1 通过特征碰撞制作毒数据
让 f(x) 表示通过网络将输入 x 传播到倒数第二层(在 softmax 层之前)的函数。我们将这一层的激活称为输入的特征空间(feature space)表示,因为它编码高级语义特征。由于 f 的高度复杂性和非线性性,我们通过下面的式子,有可能找到一个样本 x “碰撞(collide)”特征空间中的目标,同时接近输入空间的基样本 b ,
p=argminx‖f(x)−f(t)‖22+β‖x−b‖22(1)
式 1 最右边的项会使得毒样本 p 对人类标记者来说就像是基样本( β 参数化了其程度),因而被如此标记。同时,式 1 的第一项会使得毒样本向特征空间中的目标样本移动,并嵌入到目标类别分布中。在干净的模型上,这个带毒样本会被错误分类为目标。但是,如果模型在干净数据 + 毒样本上重新训练,则特征空间中的线性决策边界将被旋转,将毒样本标记成基类。由于目标样本在附近,决策边界旋转可能会无意中将目标样本与毒样本一起纳入在基类中(请注意,训练力求正确分类毒样本而非目标样本,因为后者不属于训练集)。这会使得未受干扰的目标样本(其后会在测试是被错误分类为基类)获得进入基类的“后门”。
2.2 优化程序
我们在算法 1 中展示了对式 1 进行优化以获得 p 的过程。该算法采用前向-后向分裂迭代过程(forward-backward-splitting iterative procedure)[Goldstein et al., 2014]。第一步(前向)只是梯度下降更新,以最小化到特征空间中目标样本的 L2 距离。第二个(向后步骤)是近端更新(proximal update),其最小化输入空间中与基样本的弗罗贝尼乌斯距离(Frobenius distance)。我们通过调整系数 β ,使得毒样本在输入空间中看起来足够逼真,足以骗过毫无戒心的人类观察者,认为攻击矢量图像未被篡改。

算法 1:毒样本生成
3. 对迁移学习的投毒攻击
我们首先来看迁移学习的情况,其使用预训练的特征提取网络,并且仅训练最终网络(softmax)层,使网络适应特定任务。该过程经常在工业中应用,从而在有限的数据上训练一个鲁棒的分类器。这种情况下,投毒攻击非常有效。在第 4 节中,我们将这些攻击推广到了端到端训练的情况。
我们进行了两次投毒实验。首先,在冻结除最后一层之外的所有层的权重的情况下,我们攻击了预训练的 InceptionV3 [Szegedy et al., 2016] 网络。我们的网络和数据集(ImageNet [Russakovsky et al., 2015] 狗/鱼(dog-vs-fish))与 Koh and Liang [2017] 的相同。其次,在所有层都经过训练的情况下,我们攻击由 Krizhevsky and Hinton [2009] 为 CIFAR-10 数据集修改的 AlexNet 架构 (代码见https://github.com/ashafahi/inceptionv3-transferLearn-poison)。
3.1 一击必杀
我们对迁移学习网络提出了一个简单的投毒攻击。在这种情况下,“一击必杀”是有可能的;仅通过向训练集添加一个带毒样本(由可靠的专家标记),我们对目标进行了错误的分类,成功率 100%。与 Koh and Liang [2017] 一样,我们基本上利用 InceptionV3 作为特征提取器,并重新训练其最后一个全连接层权重,从而在狗和鱼之间进行分类。我们从 ImageNet 中的每个类别中选择了 900 个样本作为训练数据,并在预处理步骤中,从训练数据集了删除了在测试数据集中也存在的重复项(如果相同的图像同时出现在训练集和测试集中,则可以选其作为基样本和目标样本,这种情况下的中毒是无价值的。我们删除了重复的图像以防止这种“作弊”。)。此后,我们剩下 1099 个测试样本(狗类有 698 个测试样本,鱼类有 401 个测试样本)。
我们从测试集中选择目标样本和基础样本,并在算法 1 中令 maxIters=1000 ,从而制作一个毒样本。由于 ImageNet 中的图像具有不同的维度,我们采用 β=β0⋅20482/(dimb)2 计算式 1 中的 β ,这里考虑了基样本的维度( dimb )和 InceptionV3 的特征空间表示层的维度(2048)。我们在实验中采用 β0=0.25 。随后,我们将毒样本添加到训练数据,中并执行冷启动训练(cold-start training)(所有未冻结的权重都被初始化为随机值)。我们使用学习率为 0.01 的 Adam 优化器,训练网络 100 个周期(epoch)。
我们进行了 1099 次实验,每次都使用不同的测试集图像作为目标样本,攻击成功率为 100% 。可以比较一下,Koh and Liang [2017] 中研究的影响函数(influence function)方法报告的成功率仅有 57% 。误分类置信度的中位数是 99.6%(图 1b)。此外,整体测试的准确度几乎不受投毒的影响,从所有实验中最初的 99.5% 一值开始,平均下降 0.2%,最差为 0.4% 。图 1a 中展示了一些示例目标样本,及其相应的毒样本。

图 1(a):示例目标和毒样本
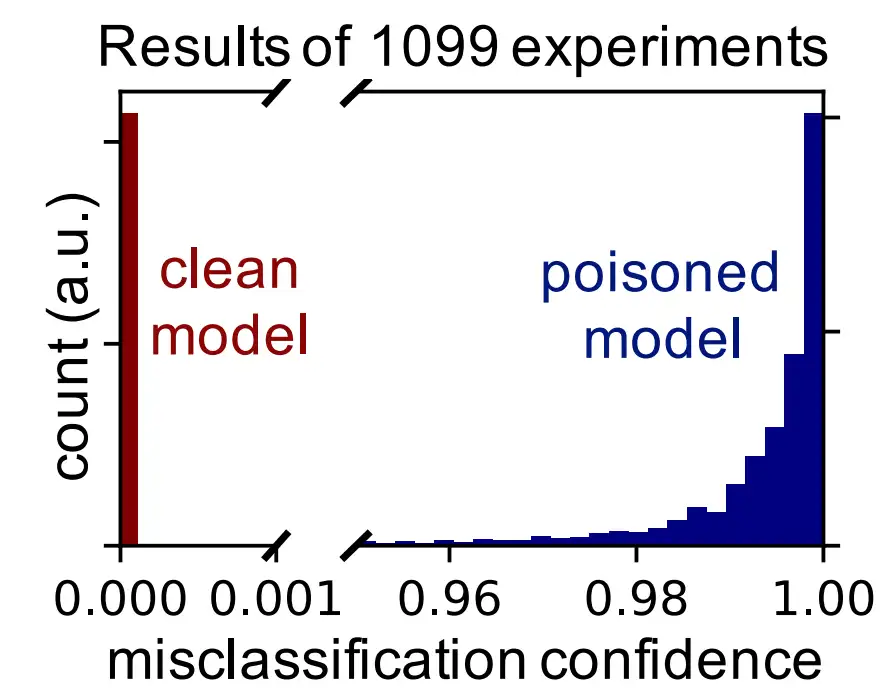
图 1(b):干净(深红色)和中毒(深蓝色)模型为目标图像预测的类别概率直方图不准确。当在带毒数据集上训练时,目标样本不仅会被错误分类,且其置信度还很高。
图 1:迁移学习投毒攻击。(a) 的顶行是 5 个随机目标样本(来自“鱼”类)。第二行是与这些目标对应的构造的毒样本。我们使用相同的基样本(第二行,最左边的图像)来构建每个毒样本。该攻击对任何基图像都有效,但如果基图像分辨率较高,则需要的迭代次数更少。当达到最大迭代次数、或目标和毒样本的特征表示相距小于 3 个单位时(欧几里德范数),我们停止毒样本生成算法。停止阈值 3 由所有训练点对之间的最小距离确定。可以看出,毒样本在视觉上与基样本无法区分(互相之间也如此)。第 3 和第 4 行展示了类似实验的样本,其中交换了目标(鱼)和基(狗)类。
请注意,通常不可能在迁移学习任务上获得 100% 的成功率。我们能够在狗对鱼任务中使用 InceptionV3 获得如此成功率的原因是因为可训练权重( 2048 )多于训练样本( 1801 )。只要数据矩阵不包含重复图像,需要求解的方程组就是欠定(under-determined)的,并且所有训练数据都肯定会出现过拟合。
为了更好地理解攻击成功的原因,我们在图 2(蓝色条和线)中绘制了干净网络和中毒网络的决策边界之间的角度偏差(即权重向量之间的角度差异)。角度偏差是在毒样本上重新训练导致的决策边界旋转,以包含基区域(base region)内的毒样本的程度。如图 2b 所示,这种偏差主要发生在第一步,这表明即使用次优的再训练超参数,攻击也可能成功。平均 23 度的最终偏差(图 2a)表明,毒样本对最终层决策边界进行了实质性改变。这些结果验证了我们的直觉,即目标的错误分类是由于决策边界的变化而发生的。
虽然我们的主要公式(式 1)通过 ℓ2 度量来提升带毒图像和基础图像之间的相似性,但是用 ℓ∞、边界为(动态范围 255 中的)2,也可以得到相同的 100% 正确率,如 Koh and Liang [2017] 中所做的那样。补充材料中介绍了实验的详细信息。
这里的实验是关于二分类任务(“狗”与“鱼”)。但,对于多分类问题,应用相同的中毒程序也是没有任何限制。在补充材料中,我们展示了额外的实验,其中引入了一个新类“cat”,我们的图片展示了程序在三向任务上仍然实现 100% 的投毒成功率,同时在干净测试中保持 96.4% 的准确率。
4. 对端到端训练的投毒攻击
我们在第 3 节中看到,对迁移学习的投毒攻击非常有效。但当所有层都可训练时,这些攻击变得更加困难。然而,使用“水印(watermarking)”技巧和多个毒样本,我们仍然可以有效地毒害端到端网络。
我们的端到端实验聚焦于一个按比例缩小的、CIFAR-10 数据集的 AlexNet 架构(我们这样做是为了缩短运行时间,因为量化这些攻击的表现需要进行每个实验、并重新训练整个网络数百次。)(详见附录中的架构细节),使用预训练权重初始化(热启动(warm-start)),并以 1.85×10−5 的学习率,使用 Adam 进行优化,批量大小(batch size)为128 ,周期(epoch)为 10。由于热启动 ,在网络重新调整以正确分类毒样本后的最后几个周期内,损失是恒定的。
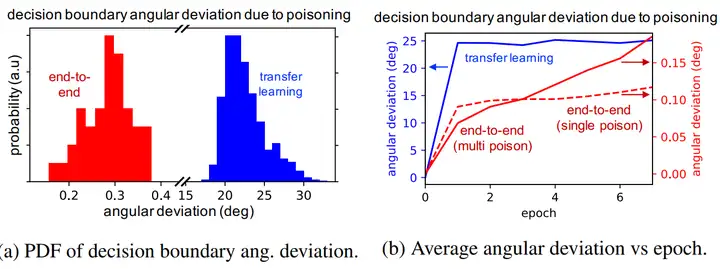
(a) 决策边界和偏差的PDF; (b) 平均角偏差与周期
图 2:使用干净数据集+毒样本训练时、与单独使用干净数据集训练时的特征空间决策边界的角度偏差。(a) 所有实验的最终(最后一个周期)角度偏差的直方图。在迁移学习(蓝色)中,特征空间决策边界有明显的旋转(平均 23 度)。相反,在我们注入 50 个毒样本的端到端训练(红色)中,决策边界的旋转可以忽略不计。(b) 大多数参数的调整是在第一阶段完成的。对于端到端的训练实验,决策边界几乎没有变化。
4.1 单毒样本攻击
我们从一个使用单个毒样本攻击网络的说明性示例开始。我们的目标是可视化毒样本对网络行为的影响,并解释:为什么端到端训练下的投毒攻击比迁移学习下更难。对于实验,我们随机选择“飞机”作为目标类,“青蛙”作为基类。对于毒样本的制作,我们采用 0.1 的 β 值和 12000 的迭代次数。图 3a 展示了通过将 193 维的深度特征向量投影到二维平面上可视化的目标、以及基和毒特征空间表示。第一维沿着连接基类和目标类质心的向量(u=μbase−μtarget),而第二维正交于 u,在 u 和 θ 确定的平面上(倒数第二层的权重向量,即决策边界的法线)。该投影使得我们能够从最能代表两个类(目标和基类)分离的角度可视化数据分布。
然后,我们通过使用干净数据 + 单个毒样本训练模型来评估我们的中毒攻击。图 3a 展示了目标、基和毒样本的特征空间表示,以及干净(未填充标记)和中毒(填充标记)模型下的训练数据。在它们干净的模型特征空间表示中,目标样本和毒样本重叠,表明我们的毒样本制作优化程序(算法 1)有效。奇怪的是,在迁移学习场景中,是最终层决策边界通过旋转以容纳基区域内的毒样本,而语气不同的是,端到端训练场景中的决策边界在带毒数据集上重新训练后是不变的,如图 2 中的红色条形图和线所示。
由此,我们做出以下重要观察:在使用带毒数据进行再训练期间,网络修改其在浅层中的低级特征提取核,以便将毒样本返回到深层中的基类分布。
换言之,毒样本的生成利用了早期层中特征提取的卷积核的缺陷,使得在特征空间中,毒样本与目标放在一起。当网络在这个毒样本上重新训练时,由于它被标记为基类,那些早期特征核的缺陷被纠正,毒样本被返回到基类分布。这一结果表明,毒样本的生成和网络训练的目标是相互对立的,因此单一毒样本可能不足以损害极端异常的目标样本。为了使攻击成功,我们必须找到一种方法来确保目标和毒样本在重新训练时不会在特征空间中分离。
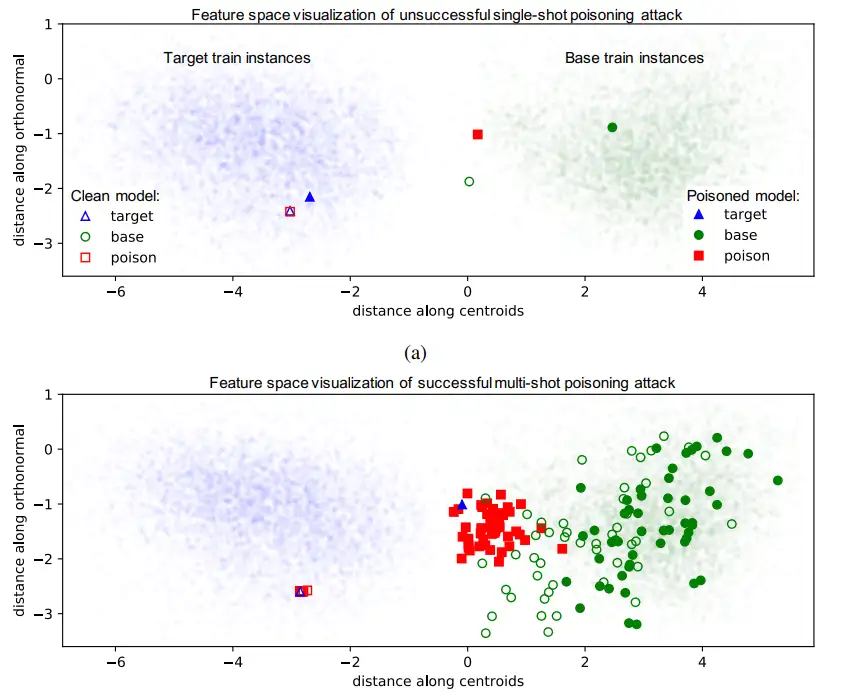
图 3
图 3:端到端训练投毒攻击的特征空间可视化。(a) 单个毒样本无法成功攻击分类器。毒样本在干净模型下的特征空间位置与目标样本的特征空间位置重叠。然而,当模型在干净 + 中毒的数据(即中毒模型)上进行训练时,毒样本的特征空间位置返回到基类分布,而目标仍然在目标类分布中。(b) 为了使攻击成功,我们从 50 个带有 30% 不透明度目标样本的“水印”的随机基样本中构建了 50 个毒样本。这使得目标样本从目标类分布(在特征空间中)中提取到基类分布中,并被错误地分类为基类。
4.2 水印:一种增强投毒攻击威力的方法
为了防止在训练过程中毒样本和目标分离,我们使用了一个简单但有效的技巧:将目标样本的低不透明度水印添加到中毒样本中,从而允许某些不可分割的特征重叠,同时保持视觉上的不同。这会将目标样本的一些特征混合到毒样本中,并且即使在重新训练后,毒样本仍保持在目标样本的特征空间附近。Chen et al. [2017] 以前曾使用过水印。但他们的工作要求在推理期间应用水印,这在攻击者无法控制目标样本的情况下是不现实的。
通过对基图像 b 和目标图像 t 进行加权组合,形成了一个具有目标不透明度 γ 的基础水印图像: b←γ⋅t+(1−γ)⋅b 。补充材料中展示了一些随机选择的毒样本。对于某些目标样本,即使不透明度高达 30%,水印也不会引人注目。图 4 展示了 60 个用于成功攻击“鸟”目标样本的毒样本。

图 4
图 4:在端到端训练场景中,60 个随机毒样本中有 12 个成功导致鸟类目标样本被错误分类为狗。在制作毒样本时,将目标鸟类样本的对抗性水印(不透明度 30%)应用于基样本。更多示例见补充材料。
4.2.1 多毒样本攻击
端到端训练场景中的投毒很困难,因为网络学习的特征嵌入可以最优地区分目标和毒样本。但是如果我们将来自不同基样本的多个毒样本引入到训练集中,又会如何呢?
为了让分类器抵抗多种毒样本,它必须学习一种特征嵌入,将所有毒样本与目标分开,同时确保目标样本保持在目标分布中。我们在实验中表明,使用高度多样化的基样本可以防止中等规模的网络学习与基样本不同的目标特征。因此,当网络被重新训练时,目标样本与毒样本一起被拉向基分布,并且攻击通常是成功的。这些相互作用如图 3b 所示。
在图 2 中,我们观察到,即使在多次投毒实验中,最后一层的决策边界依然保持不变,这表明,在迁移学习中,投毒成功的机制完全不同于端到端的训练场景。迁移学习通过旋转决策边界以包含目标,从而对毒物做出反应,而端到端训练通过将目标拉入基分布(在特征空间中)来做出反应。在对带毒数据集进行再训练时,端到端场景中的决策边界保持不变(变化几分之一度),如图 2 所示。
为了量化中毒样本的数量如何影响成功率,我们对 1 到 70(增量为 5)之间的每个毒样本进行了实验。实验中使用从测试集随机选择的目标样本。每个毒样本都是从测试集中的随机基样本生成的(这导致毒样本之间存在很大的特征多样性)。我们使用 30% 或 20% 的水印不透明度,来增强毒样本和目标之间的特征重叠。(超过 30 次随机试验的)攻击成功率如图 5b 所示。对 CIFAR-10 中不同的目标-基类对重复了 30 组实验,以验证成功率不依赖于类别。我们还尝试降低了不透明度,并观察到了成功率的下降。成功率随着毒样本的数量增加而增加。使用 50 个毒样本后,鸟对狗任务的成功率约为 60%。请注意,我们仅在目标被归类为基样本时才认为攻击成功;即使目标样本被错误分类为基类以外的类,也认为攻击是不成功的。
我们可以通过针对数据异常值(targeting data outliers)来提高这种攻击的成功率。这些目标远离它们类别中的其他训练样本,因此翻转它们的类别标签应该更容易。我们以分类置信度最低(但仍正确分类)的 50 架“飞机”为目标,每次攻击使用 50 只“毒蛙”来攻击它们。这种攻击的成功率为 70%(图 5a),比随机选择的目标高 17% 。
总而言之,端到端场景下的干净标签攻击需要多种技术才能发挥作用:(1) 通过算法 1 进行优化,(2) 毒样本的多样性,以及 (3) 水印。
在补充材料中,我们提供了一个留一法消融研究(leave-one-out ablation study),其中包含 50 个毒样本,从而证明要想使中毒成功需要上述所有的三种技术。
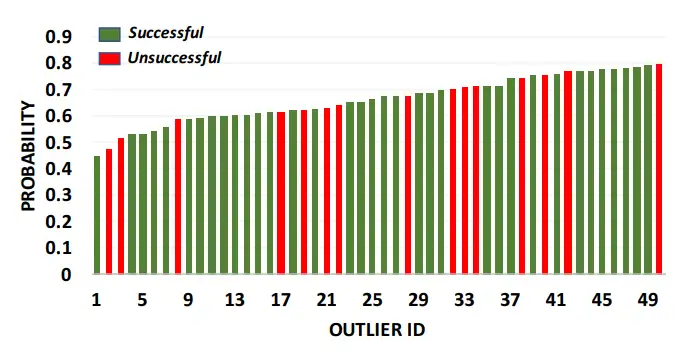
图 5(a):攻击最离群的目标飞机。条形表示攻击前目标样本的概率(使用预训练网络计算)。着色表示攻击是否成功。每个实验都使用了 30% 的水印不透明度和 50 个毒样本。在这 50 个异常值中,攻击成功率为 70%(相比之下,随机目标为 53%)。
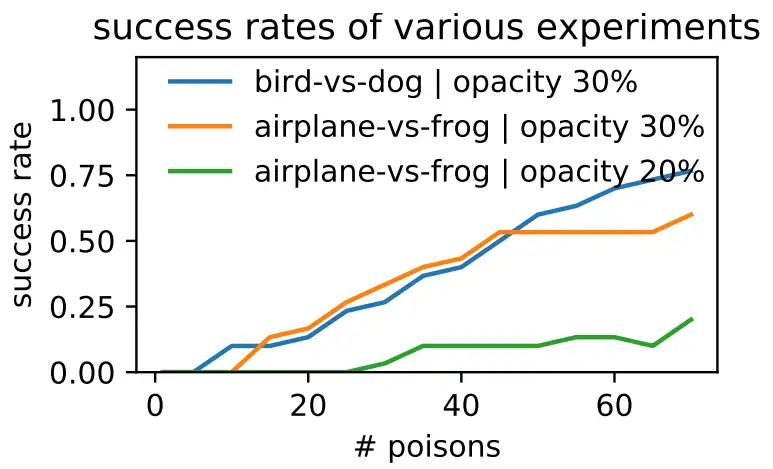
图 5(b):来自不同基类的不同目标的攻击成功率,作为使用的毒样本数量和添加到基样本的不同目标的不透明度的函数。
图 5:攻击异常值和随机目标的成功率。虽然攻击非异常值也是有可能的,但攻击异常值可以增加成功的机会。
5. 结论
我们研究了有目标的干净标签投毒方法,这些方法在训练时攻击网络,目的是操控测试时的行为。这些攻击很难检测到,因为它们涉及非可疑(正确标记)的训练数据,并且不会降低非目标样本的表现。我们提出的攻击方式会在特征空间中与目标图像发生冲突,从而使网络难以辨别两者。这些攻击在迁移学习场景中非常强大,并且可以通过使用多个毒图像和水印技巧,在更一般的环境中也变得十分强大。
使用毒样本进行训练类似于用于防御逃逸攻击的对抗训练技术(Goodfellow et al. [2015])。毒样本在这里可以看作是基类的对抗样本。虽然对于被错误分类为目标类的基类对抗样本,我们的带毒数据集训练确实使网络更具鲁棒性,但它也会导致未改变的目标样本被错误分类作为基样本。本文利用了对抗训练的这种副作用,值得进一步研究。
许多神经网络都是使用容易被攻击者操纵的数据源来训练的。我们希望这项工作能够引起人们对数据可靠性和来源这一重要问题的关注。
- Author:faii
- URL:https://www.faii.top/article/6976af83-3ad8-46f1-baf0-36ccfb32c99f
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts